609 private links
I recently reworked my LaTeX template underlying my CV to be compliant with PDF/A-3U, and now I keep noticing chatter about PDF/A compliance or PDF accessibility in my feeds. It's true what they say: once you learn something, you start noticing it :-)
Let's collect notes here.
Accessibility of STEM documents
- https://tex.social/accessibility-of-stem-documents-talk-at-pdf-days-2025-in-berlin - blog post
- https://pdfa.org/the-winning-technical-poster-at-pdf-days-europe-2025 - all posters from the PDF Days Europe 2025 conference (many of them are about accessibility), very interesting!
- https://pdfa.org/presentation/tagged-and-accessible-pdf-with-latex-revisited - session at the same conference on "tagged and accessible PDF with LaTeX" with references to several works by the core LaTeX developers.
Reduction-oxidation sum reactions are typically written as two lines (red/ox) with a sum reaction underneath. Here is an example of how to typeset this building on the reactions environment from the awesome chemmacros package.
My goals with this custom environment was to retain chemical reaction numbering (with sub-numbering for the redox reactions) and horizontally align everything on the reaction arrow.
The solution is not automated all the way so may require some fiddling of horizontal or vertical distances to make it look great.
Load chemmacros in the preamble:
\usepackage[
% *minimal* specifies the following set of always loaded modules:
% acid-base, charges, nomenclature, particles, phases, symbols
minimal=true,%
modules={reactions}%
]{chemmacros}and define the custom environment I like to call subreactions:
\makeatletter
\newenvironment{subreactions}{%
\refstepcounter{reaction}%
\protected@edef\theparentequation{\thereaction}%
\setcounter{parentequation}{\value{reaction}}%
\setcounter{reaction}{0}%
\def\thereaction{\theparentequation\alph{reaction}}%
\ignorespaces
}{%
\setcounter{reaction}{\value{parentequation}}%
\ignorespacesafterend
}
\makeatotherI did not come up with that on my own, I got a lot of help and found inspiration in the work of others.
Here is the end result (screenshot from my thesis), the well-known water splitting reaction expressed as hydrogen reduction and water oxidation:
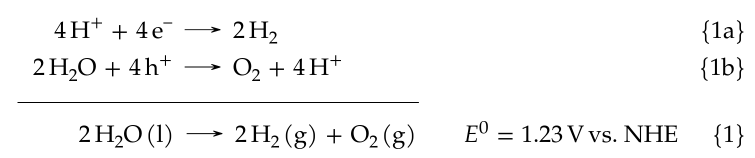
which was created with this code:
\begin{subreactions}\begin{reactions}%
4 \proton{} + 4 \electron{} &-> 2 \hydrogen{} && $\qquad\qquad\qquad\qquad$ \AddRxnDesc{Hydrogen~evolution} \"\label{rxn:hydrogen-evolution}\" \\%
2 \water{} + 4 \hole{} &-> \oxygen{} + 4 \proton{} && $\qquad\qquad\qquad\qquad$ \AddRxnDesc{Oxygen~evolution} \"\label{rxn:oxygen-evolution}\"%
\end{reactions}\end{subreactions}%
\addtocounter{reaction}{-1}%
\vspace{-\baselineskip}%
% note that the following lengths must be adjusted if
% the horizontal extent of any reactions are changed!
\hspace{13mm}%
\begin{minipage}{59mm}%
\vspace{-\baselineskip}%
\hrulefill%
\end{minipage}%
\begin{reaction}%
\qquad{}\qquad{}\quad{} 2 \water\lqd{} -> 2 \hydrogen\gas{} + \oxygen\gas{} $\quad\enspace\enspace E^0=\qty{1.23}{\voltNHE}$ \AddRxnDesc{Overall~water~splitting} \"\label{rxn:water-splitting}\"%
\end{reaction}%
This solves a major shortcoming when authoring documents in Quarto or R Markdown that generate both PDF and HTML output. MathJax lets the author use LaTeX commands in the source that translate into proper output in the HTML, but before this work there was no support for siunitx v3. This work can be said to take over where burnpanck/MathJax-siunitx left off.
To use it, I copied siunitx.js from its repo to my Quarto project and then made Quarto add it to the published site by setting the following in the project/document YAML:
project:
resources:
- "path/to/siunitx.js"
format:
html:
html-math-method:
method: mathjax
url: "https://cdn.jsdelivr.net/npm/mathjax@3/es5/tex-chtml.js"
include-in-header:
text: |
<script>
window.MathJax = {
loader: {
load: ['[custom]/siunitx.js', '[tex]/html'],
paths: { custom: './path/to/' }
},
tex: {
packages: { '[+]': ['siunitx', 'html'] },
siunitx: {
'per-mode': 'power'
}
}
};
</script>And that should give you siunitx v3 commands in your Quarto manuscript :-)
Note that if you also want your notebooks to benefit from siunitx-pcc, you will need to symlink (or copy) the siunitx.js file into their top-level directory (which is ./notebooks) or otherwise siunitx macros will not render as paths: { custom: './path/to/' } is relative to their top-level directory and not (as you might think) the Quarto project root.
I have found that re-creating the directory structure mkdir -p notebooks/path/to; cd notebooks/path/to and then symlinking ln -s ../../../path/to/siunitx.js . works (don't forget to add another resources line: - "notebooks/path/to/siunitx.js").
In short, siunitx-pcc lets you use almost all siunitx macros.
- https://github.com/limefrogyank/siunitx-pcc
- https://github.com/quarto-dev/quarto-cli/discussions/6168#discussioncomment-11545200
- https://github.com/mathjax/MathJax-third-party-extensions/issues/47
- https://github.com/burnpanck/MathJax-siunitx/issues/14
- https://github.com/burnpanck/MathJax-siunitx/issues/13
- https://old.reddit.com/r/LaTeX/comments/1bj8p7c/whats_your_experience_transitioning_to_quarto/m1p0m4p
Let's say you have a very large Zotero library, from which you export a likewise large BibLaTeX file, say full-library.bib.
In your document you load that large BIB-file (because that's easy), \addbibresource{full-library.bib}, but naturally cite only a subset of works.
Now you want to share the source code for this document with someone else, and provide them with a BIB-file so they can recompile it if they wish. Can we produce a BIB-file containing only the entries that were actually cited in the document?
Yes, we can. biber has built-in support for this scenario. Just make sure your latest compilation produced a proper .bcf file, then:
biber --output_format=bibtex --output_resolve document.bcfwhich will create document_biber.bib, a properly formatted BibLaTeX BIB-file containing only the subset of works from your library that were actually cited in this document.
I'm afraid I don't remember where I learned this.

Using biblatex with a numeric style and a book class with frontmatter/mainmatter, would it be possible to have all citations in the frontmatter appear last in the list of references, as if the frontmatter (from biblatex's point of view) appeared after the mainmatter?
\documentclass{book}
\usepackage[utf8]{inputenc}
\usepackage[backend=biber,sorting=none,style=nature]{biblatex}
\usepackage{filecontents}
\begin{filecontents}{\jobname.bib}
@misc{hydrogen,
author = {Author, A.},
year = {2001},
title = {Alpha}}
@misc{neodymium,
author = {Luthor, Lex.},
year = {2002},
title = {Bravo}}
\end{filecontents}
\addbibresource{\jobname.bib}
\frontmatter
\cite{neodymium}
\mainmatter
\cite{hydrogen}
\backmatter
\printbibliography[title={List of references}]
\end{document}In the above MWE, references in the "List of references" are printed in the same order as they were given in the document, so neodymium would be listed before hydrogen in the "List of references".
This also means that the citation in the frontmatter would be labelled [1] in the text and the first citation in the mainmatter would be labelled [2].
This is just as expected with the numeric style as often used in science and engineering theses.
I wonder if there is some way to make the first citation in the mainmatter be [1] (because it might be jarring for the reader to see the first citation in the first chapter be something like [11], it may make them wonder what they missed), without having a separate \printbibliography for the frontmatter (nor using refsection or refsegments, because I don't think they will help in this case). Preferably any citations in the frontmatter would simply be appended to the end of "List of references", as if the frontmatter was processed after the frontmatter by biblatex.
I think this would be hard to achieve. But I'd like to hear if anyone knows better?
Would something like this be possible? Have I missed something obvious?
I have read the Sorting section in the biblatex manual, and read these related (but not-very-pertinent) questions on TeX.SE
- https://tex.stackexchange.com/questions/540610/numbering-issue-in-printbiblography/540615
- https://tex.stackexchange.com/questions/306678/biblatex-have-two-separate-bibliographies-with-consecutive-numbering
- https://tex.stackexchange.com/questions/244150/citations-out-of-order-with-appendix-and-split-bibliographies-in-backmatter
I am heavily indebted to Hoger Gerhardt for posting his example on TeX.SE.
I chose to put a DOI symbol (thanks to the Academicons package) at the end of each bib entry. I think it looks rad.
\usepackage[backend=biber,date=year,doi=true,url=false,style=nature]{biblatex}
\usepackage{fontawesome5}
\usepackage{academicons}
\usepackage{hyperref}
\renewbibmacro*{finentry}{%
\iffieldundef{doi}{%
% Entry lacks DOI
\iffieldundef{url}{%
% Entry lacks URL and DOI
\finentry%
}{%
% Entry has URL but lacks DOI
% Show URL hyperlink as icon (concsiously not using same icon as our "external hyperlinks")
\finentry\space%
\href{\thefield{url}}{\footnotesize\faIcon{link}}%
}%
}{%
% Entry has DOI \aiDoi
\finentry\space%
% lower the DOI symbol a little to align better with baseline
\href{https://doi.org/\thefield{doi}}{\raisebox{-0.1ex}{\aiDoi}}%
}%
}%
% suppress output of DOI field (hide both DOI label and string)
\DeclareFieldFormat{doi}{}%Here's an example of how the typeset bibliography entries look like (please excuse the poor resolution, the screenshotter suddenly decided to drop the quality):
![]()

Learn how to create unit tests for scientific papers in Python using PyTest.
Have you also been in the situation where you need to write up your latest Raman spectra of ZnO?
And just exasperated at the thought of typing up all those mode assignments using LaTeX math notation (because honestly, it looks good).
I created this macro, \nonresmode{E2h}[E2l][long][diff], to make it easier to write.
Now all I have to do is write, for example, \nonresmode{A1LO}, and LaTeX does all the work and produces a nicely typeset label.
Here is some example LaTeX source:
Non-resonant Raman with green laser excitation (\qty{532}{\nm}).
All the observed Raman modes could be assigned to either a fundamental mode
(\nonresmode{E2l}[][long], \nonresmode{A1TO}, \nonresmode{E1TO}, \nonresmode{E2h}[][long],
\nonresmode{E1LO}, \nonresmode{A1LO}), an overtone (\nonresmode{2E2l}[][long], \nonresmode{2E1LO},
\nonresmode{2A1LO}), a sum mode (\nonresmode{E2h}[E2l][long], \nonresmode{E2h}[2E2l][long],
\nonresmode{2E2h}[E2l][long], $2(\nonresmode{E2h}[E2l][long])$) or
a difference mode (\nonresmode{E2h}[E2l][long][diff]).and the resulting output:

And here is the macro definitions (to avoid repeating the main "correspondence table" between the short-codes and the typeset text,
I opted to define multiple functions. I also made use of the beautiful macro by egreg that defines a case-like environment:
% defines a case environment
% code taken from a TeX.SE answer by egreg
% https://tex.stackexchange.com/a/451094/10824
% fantastic piece of code, works beautifully, for an arbitrary number of cases
\ExplSyntaxOn
\NewExpandableDocumentCommand{\stringcase}{mO{}m}{%
\str_case_e:nnF { #1 } { #3 } { #2 }
}
\ExplSyntaxOff
% not meant to be exposed to user
\NewDocumentCommand{\NonResonantModesShort}{m}{%
\stringcase{#1}[\textbf{??}]{%
% note, \text{} inside math environment will obey font settings from
% surrounding environment (e.g., bold) but \mathrm{} will not which
% makes it better for this purpose
% {shortcode}{LaTeX typeset text}
{E2l}{\ensuremath{E_{2\mathrm{l}}}}%
{A1TO}{\ensuremath{A_{1(\mathrm{TO})}}}%
{E1TO}{\ensuremath{E_{1(\mathrm{TO})}}}%
{E2h}{\ensuremath{E_{2\mathrm{h}}}}%
{E1LO}{\ensuremath{E_{1(\mathrm{LO})}}}%
{A1LO}{\ensuremath{A_{1(\mathrm{LO})}}}%
{2E2l}{\ensuremath{2E_{2\mathrm{l}}}}%
{2E2h}{\ensuremath{2E_{2\mathrm{h}}}}%
{2E1LO}{\ensuremath{2E_{1(\mathrm{LO})}}}%
{2A1LO}{\ensuremath{2A_{1(\mathrm{LO})}}}%
}%
}
% not meant to be exposed to user
\NewDocumentCommand{\NonResonantModesLong}{m}{%
\stringcase{#1}[\textbf{??}]{%
{E2l}{\ensuremath{E_{2\mathrm{(low)}}}}%
{A1TO}{\ensuremath{A_{1(\mathrm{TO})}}}%
{E1TO}{\ensuremath{E_{1(\mathrm{TO})}}}%
{E2h}{\ensuremath{E_{2\mathrm{(high)}}}}%
{E1LO}{\ensuremath{E_{1(\mathrm{LO})}}}%
{A1LO}{\ensuremath{A_{1(\mathrm{LO})}}}%
{2E2l}{\ensuremath{2E_{2\mathrm{(low)}}}}%
{2E2h}{\ensuremath{2E_{2\mathrm{(high)}}}}%
{2E1LO}{\ensuremath{2E_{1(\mathrm{LO})}}}%
{2A1LO}{\ensuremath{2A_{1(\mathrm{LO})}}}%
}%
}
% not meant to be exposed to user
\NewDocumentCommand{\NonResonantModesLogic}{m O{short}}{%
\IfNoValueTF{#2}{%
% arg #2 (optional) not given, proceed as "short"
\NonResonantModesShort{#1}%
}{%
% arg #2 (optional) was given, check if it is "long"
\ifthenelse{\equal{#2}{long}}{%
% "long" was given
\NonResonantModesLong{#1}%
}{%
% arg was given, but is not equal to "long"
% check if it is "short"
\ifthenelse{\equal{#2}{short}}{%
\NonResonantModesShort{#1}%
}{%
% arg was neither "long" nor "short", something else
\NonResonantModesShort{}%
}%
}%
}%
}
% Non-resonant Raman modes of ZnO
% \nonresmode{E2h}[E2l][long][diff]
% Use \nonresmode like this:
% \nonresmode{E2l} => E2l
% \nonresmode{E2l}[][long] => E2low
% \nonresmode{} => ??
% \nonresmode => ERROR
% \nonresmode{E2l}[E2h] => E2l+E2h
% \nonresmode{E2l}[E2h][][diff] => E2l-E2h
% \nonresmode{E2l}[E2h][long] => E2low + E2high
% only specify optional arguments if necessary, i.e.,
% please don't do \nonresmode{E2l}[][][], but please do \nonresmode{E2l}
% remember, optional arg "o" will supply the special -NoValue- marker if not given
% the arg O{sum} is an optional arg with the default value "sum"
\NewDocumentCommand{\nonresmode}{m o O{short} O{sum}}{%
\IfNoValueTF{#2}{%
% no arg #2 was given, which means we are typesetting a single mode
% if no arg #2 was given, then we can disregard #4
\IfNoValueTF{#3}{%
% this way, if #3 was not given, we avoid passing the special -NoValue- marker
\NonResonantModesLogic{#1}%
}{%
% if #3 was given, pass it on, unless it was empty
\ifthenelse{\isempty{#3}}{%
\NonResonantModesLogic{#1}%
}{%
\NonResonantModesLogic{#1}[#3]%
}%
}%
}{%
% If optional arg #2 was given and is empty, perform the same code as if -NoValue-
\ifthenelse{\isempty{#2}}{%
\IfNoValueTF{#3}{%
% this way, if #3 was not given, we avoid passing the special -NoValue- marker
\NonResonantModesLogic{#1}%
}{%
% if #3 was given, pass it on, unless it was empty
\ifthenelse{\isempty{#3}}{%
\NonResonantModesLogic{#1}%
}{%
\NonResonantModesLogic{#1}[#3]%
}%
}%
}{%
% if #2 is not -NoValue- nor empty, then just assume that it is one of the mode shortcodes
% (we don't try to check that it is in fact part of that set)
% But first, determine if we are writing "sum" or "diff" modes
% (note that we assume that #4 has a value, since it is the last arg we never expect it%
% to be given explicitly empty)
\ifthenelse{\equal{#4}{diff}}{%
% Since #4 has a default, we can simplify this if-else to only check for "diff"
% and we can then assume that the else-clause matches "sum"
% But note that arg #3 may have been given explicity empty, [], thus overriding the default
% so we must check for that
\ifthenelse{\isempty{#3}}{%
% Note, to get consistent spacing around the +/- sign whether the
% call to \nonresmode{} is surrounded by math mode or not, it is
% good to surround everything in ensuremath{} here
% Also, for "short" mode, I want to kill the space surrounding the +/- sign
% (to keep it compact, which is probably what the user wants in "short" mode)
\ensuremath{\NonResonantModesLogic{#1}{-}\NonResonantModesLogic{#2}}%
}{%
\ifthenelse{\equal{#3}{long}}{%
\ensuremath{\NonResonantModesLogic{#1}[#3]-\NonResonantModesLogic{#2}[#3]}%
}{%
\ensuremath{\NonResonantModesLogic{#1}{-}\NonResonantModesLogic{#2}}%
}%
}%
}{%
\ifthenelse{\isempty{#3}}{%
\ensuremath{\NonResonantModesLogic{#1}{+}\NonResonantModesLogic{#2}}%
}{%
\ifthenelse{\equal{#3}{long}}{%
\ensuremath{\NonResonantModesLogic{#1}[#3]+\NonResonantModesLogic{#2}[#3]}%
}{%
\ensuremath{\NonResonantModesLogic{#1}{+}\NonResonantModesLogic{#2}}%
}%
}%
}%
}%
}%
}Could we cross-reference objects (tables, figures, etc.) that exist in the attached papers (whose code-base is foreign to the thesis) while also having these cross-references target the appropriate paper in the List of Papers, with the aid of the cleveref, caption and hyperref packages?
To clarify, for a compilation PhD thesis, where the thesis itself is created using LaTeX, but where the attached papers (hence the compilation part in the thesis) may or may not have been created using LaTeX (even if they were created using LaTeX, their codebase is not available to the thesis at runtime).
So we need to setup some sort of static list of manually created \label{}s, that should occupy a counter and namespace separate from the thesis' own figures, tables, etc.
Preamble, literally
Uppsala university has a thesis template (my version, LuaLaTeX-based) that defines a listofpapers environment (the details of which are not important right now) that allows us to create a List of Papers and easily assign a label for each paper, like this:
\begin{listofpapers}
\item\label{P1}
Li, C.; Ahmed, T.; Ma, M.; Edvinsson, T.; Zhu, J. %
Photocatalytic properties of ZnO/CdS nanoarrays\\%
\item \label{P2}
Ahmed, T.; Edvinsson, T. %
Photocatalytic activity of ultrasmall ZnO\\%
\end{listofpapers}The above works in conjunction with the following definitions in the preamble:
\usepackage{cleveref}
\crefname{listofpapersc}{\textbf{\textsc{paper}}}{\textbf{\textsc{papers}}}
\Crefname{listofpapersc}{\textbf{\textsc{paper}}}{\textbf{\textsc{papers}}}
\creflabelformat{listofpapersc}{#2\textbf{\textsc{#1}}#3}to give a nicely formatted Paper 1 (in small-caps in this case) in the text when we issue \cref{P1}.
Solution: new floating environment and a custom cleveref format per paper
I have limited time to type this up, so here goes.
\usepackage{newfloat} % for the DeclareFloatingEnvironment cmd
\usepackage[nameinlink]{cleveref}
\crefname{listofpapersc}{\textbf{\textsc{paper}}}{\textbf{\textsc{papers}}}
\Crefname{listofpapersc}{\textbf{\textsc{paper}}}{\textbf{\textsc{papers}}}
\creflabelformat{listofpapersc}{#2\textbf{\textsc{#1}}#3}
\DeclareFloatingEnvironment[within=none]{tableP1}
\crefformat{tableP1}{\textsc{#2tab.~#1#3}~of\space\cref{P1}}
\Crefformat{tableP1}{\textsc{#2Tab.~#1#3}~of\space\cref{P1}}
\crefrangeformat{tableP1}{\textsc{tabs.~#3#1#4--#5#2#6}~of\space\cref{P1}}
\Crefrangeformat{tableP1}{\textsc{Tabs.~#3#1#4--#5#2#6}~of\space\cref{P1}}
\crefmultiformat{tableP1}{%
\scshape tabs.~#2#1#3}{%
\:\&\:#2#1#3~\textnormal{of\space}\cref{P1}}{%
, #2#1#3}{%
\:\&\:#2#1#3~\textnormal{of\space}\cref{P1}}
\Crefmultiformat{tableP1}{%
\scshape Tabs.~#2#1#3}{%
\:\&\:#2#1#3~\textnormal{of\space}\cref{P1}}{%
, #2#1#3}{%
\:\&\:#2#1#3~\textnormal{of\space}\cref{P1}}
\crefrangemultiformat{tableP1}{%
\scshape tabs.~#3#1#4--#5#2#6}{%
\:\&\:#3#1#4--#5#2#6~\textnormal{of\space}\cref{P1}}{%
, #3#1#4--#5#2#6}{%
\:\&\:#3#1#4--#5#2#6~\textnormal{of\space}\cref{P1}}
\Crefrangemultiformat{tableP1}{%
\scshape Tabs.~#3#1#4--#5#2#6}{%
\:\&\:#3#1#4--#5#2#6~\textnormal{of\space}\cref{P1}}{%
, #3#1#4--#5#2#6}{%
\:\&\:#3#1#4--#5#2#6~\textnormal{of\space}\cref{P1}}and repeat the last block (everything down from DeclareFloatingEnvironment) for figureP1, and for tableP2, figureP2, etc.
And then, for the pièce de résistance, in one fell swoop we abuse both the listofpapers environment and the phantomcaption command to create the labels that our cross-references will target:
\begin{listofpapers}
\item\label{P1}
Li, C.; Ahmed, T.; Ma, M.; Edvinsson, T.; Zhu, J. %
Photocatalytic properties of ZnO/CdS nanoarrays\\%
\bgroup
\captionsetup{type=figureP2}
\phantomcaption\label{fig:P1-schematic}
\phantomcaption\label{fig:P1-mechanism}
[... more figure labels as necessary ...]
\egroup
\bgroup
\captionsetup{type=tableP2}
\phantomcaption\label{tab:P1-parameters}
\phantomcaption\label{tab:P1-rates}
[... more table labels as necessary ...]
\egroup
\item \label{P2}
Ahmed, T.; Edvinsson, T. %
Photocatalytic activity of ultrasmall ZnO\\%
\end{listofpapers}captionsetup needs to be constrained by an environment (the manual suggests a minipage, which works fine but occupies a little bit of vertical space on the page), and it turns out group works in this context and has the added benefit of occupying no space in the List of Papers.
With that, we can simply type \cref{fig:P1-schematic} in the source to produce a nicely formatted cross-reference in the output document. The use of small-caps, abbreviated label names, and the trailing of paper X is my way to make these references contrast with the normal, in-thesis cross-references.
Here's an example of how the typeset cross-references look like:

Links and notes
- https://tex.stackexchange.com/questions/383587/plural-cref-with-custom-unnumbered-subsections
- https://tex.stackexchange.com/questions/597048/cleveref-fig-for-citing-multiple-subfigures-from-the-same-figure-but-figs
- https://gist.github.com/ummels/3428745
- https://reddit.com/r/LaTeX/comments/5gv6al/reference_multiple_list_items_in_single/
- the cleveref manual
- the caption and subcaption manuals
A small wrinkle when using bib2df together with bib2gls: the latter does not tolerate empty cross-reference fields.
bib2df::df2bib() takes a tibble and generates the entries.bib file, and since the tibble by necessity contains one column for each field, any entries with empty see fields get converted by bib2df::df2bib() to see={}. The presence of any glossary entry with an empty see={} field causes bib2gls to fail:
Processing resource thesis-1.glstex.
Parsing fields for entry 'absorption_coefficient'
Checking field aliases for absorption_coefficient.
Value=>user1={}
>> name={{}\ensuremath{\alpha}}
=>> name={{}\ensuremath{\alpha}}
>> first={absorption coefficient, \ensuremath{\alpha}}
=>> first={absorption coefficient, \ensuremath{\alpha}}
>> text={absorption coefficient}
=>> text={absorption coefficient}
>> description={absorption coefficient}
=>> description={absorption coefficient}
>> user1={}
=>> user1={}
>> see={}
=>> see={}
Checking cross-references for: absorption_coefficient
Field alias not set.
Error: EOFException
com.dickimawbooks.texparserlib.TeXParser.popStack(TeXParser.java:2635)
com.dickimawbooks.texparserlib.TeXObjectList.popArg(TeXObjectList.java:1294)
com.dickimawbooks.texparserlib.TeXObjectList.popArg(TeXObjectList.java:1275)
com.dickimawbooks.bib2gls.Bib2GlsEntry.initSeeRef(Bib2GlsEntry.java:4710)
com.dickimawbooks.bib2gls.Bib2GlsEntry.initCrossRefs(Bib2GlsEntry.java:4694)
com.dickimawbooks.bib2gls.GlsResource.processBibList(GlsResource.java:6722)
com.dickimawbooks.bib2gls.Bib2Gls.process(Bib2Gls.java:2706)
com.dickimawbooks.bib2gls.Bib2Gls.main(Bib2Gls.java:6616)As you can see, other fields may be empty, but not the see field.
This is not a bug in either bib2df:: or bib2gls, and I don't expect either project to "fix" this issue. The former is not meant for and has no notion of glossaries, and the latter is not really expecting us to be generating the .bib file, so why should there be empty see fields?
To work around this I suggest removing all lines with see={} fields from the entries.bib file, here an example using sed:
sed -i '"/[Ss]ee\s*=\s*{}/d" entries.bibI simply added this sed command to the R chunk that calls bib2df::df2bib().
I should probably add that my reason for generating the glossary bib-file from R in the first place was to make use of the excellent constants library.
Notes and links
This behaviour was observed on Ubuntu 22.04, R 4.1.3, TeXLive 2022, glossaries-extra 1.50, bib2gls 3.2, bib2df 1.1.1.
- I figured out how to rename the headers, which involved editing longtab definitions, always a little tricky...
- Breaking issue with bib2gls v2.9, fixed by bib2gls author. Same issue on git.solarchemist.se. Related missing field "name" warning.
but more work remains to be done.
Good resources:
The SI system
- A comprehensive (SI) units package for LaTeX, by Joseph Wright. I cannot recommend this package enough for all scientific or technical documents. CTAN.
Code examples
- Semiconductor pn-junction diagram in TikZ, by Erwann Fourmond (2016)
- Schematic TEM in TikZ, by Eric Jensen (2012)
- Oxidation of iron surface under a blob of water in TikZ, by Jason Waskiewicz (2010)
- Designing a business card in LaTeX, by Olivier Peters. Github repo.
Templates
- LaTeX packages for CVs, resumés
- PhD thesis template for Cambridge university Engineering dept. Supports LaTeX, XeLaTeX and LuaLaTeX.
Integration with R
The ability to integrate any kind of R output into our LaTeX document is very useful, and the technology has reached a high degree of sophistication with knitr and tikzDevice (on the R side) and TikZ/PGF (on the LaTeX side).
- TikZDevice, an R package for producing graphics output as PGF/TikZ code for use in TeX documents. In other words, we start in R, generate an image, and export it to a TikZ picture. tikzDevice was developed around 2009 (here's an early demo) in concert with pgfSweave (this was before knitr entered the scene).
- dvir, offers the inverse approach to tikzDevice: we start in R, generate a TikZ picture, convert that to DVI, then import (and integrate) the result back into R. dvir is less popular than tikzDevice, and is currently not listed on CRAN (in fact, it clashes with an existing completely unrelated package named
dvir), but appears to have solid technical underpinnings, with LuaTeX support and LaTeX math support.
Integration with Inkscape
- SVG2TikZ, formally known as Inkscape2TikZ, is an Inkscape extension for exporting SVG paths as TikZ/PGF code.
Integration with Microsoft PowerPoint
- IguanaTeX is a PowerPoint add-in which allows you to insert LaTeX equations into your PowerPoint presentation.
Integration with git
- gitinfo2-latexmk, small tool that integrates latexmk and gitinfo2.
Integration with Zotero
- Better BibTeX, a Zotero extension that makes Zotero effective for LaTeX users.
Integration with the web
- TeX commands available in MathJax, a comprehensive list of all commands available in MathJax v2.7.1, by Carol Burns and edited by MathJax creator Davide Cervone. MathJax v2.7 is still widely used, but has technically been superseded by v3. MathJax.
- KaTeX, developed by Khan Academy. Known to be faster than MathJax, but supporting a smaller subset of TeX/LaTeX functions. Differences between the projects appear to be shrinking, though.
Cloud-based LaTeX
Other packages
- Beamer, package for producing presentations and slides. Github.
- FiXme, collaborative annotation tool for LaTeX. Github.
Tips and tricks
- https://www.overleaf.com/gallery/tagged/cv
- https://ctan.org/pkg/moderncv (examples: classic, fancy, oldstyle)
- https://github.com/posquit0/Awesome-CV (example)
- https://ctan.org/pkg/curve
- https://ctan.org/pkg/limecv (example)
- https://ctan.org/pkg/europasscv (example)
- https://ctan.org/pkg/europecv (example)